Image-text contrastive learning models such as CLIP and OpenCLIP have demonstrated strong task transfer ability. The high generality and usability of these visual models is achieved via a web-scale data collection process to ensure broad concept coverage, followed by expensive pre-training to feed all the knowledge into model weights. Alternatively, we propose REACT, REtrieval-Augmented CusTomization, a framework to acquire the relevant web knowledge to build customized visual models for target domains. We retrieve the most relevant image-text pairs (~3% of CLIP pre-training data) from the web-scale database as external knowledge, and propose to customize the model by only training new modualized blocks while freezing all the original weights. The effectiveness of REACT is demonstrated via extensive experiments on classification, retrieval, detection and segmentation tasks, including zero, few, and full-shot settings. Particularly, on the zero-shot classification task, compared with CLIP, it achieves up to 5.4% improvement on ImageNet and 3.7% improvement on the 20 image classification datasets in ELEVATER benchmark.
Given a downstream visual task, REACT considers a
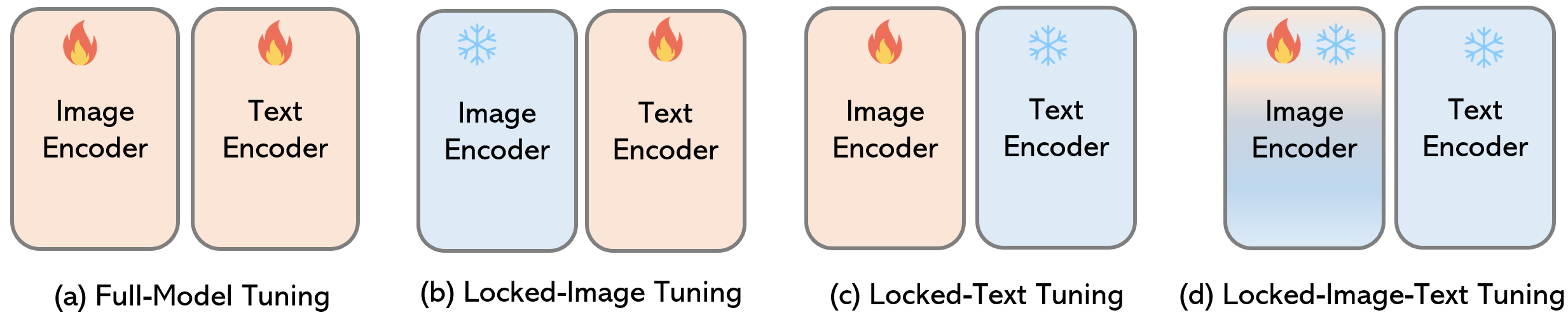
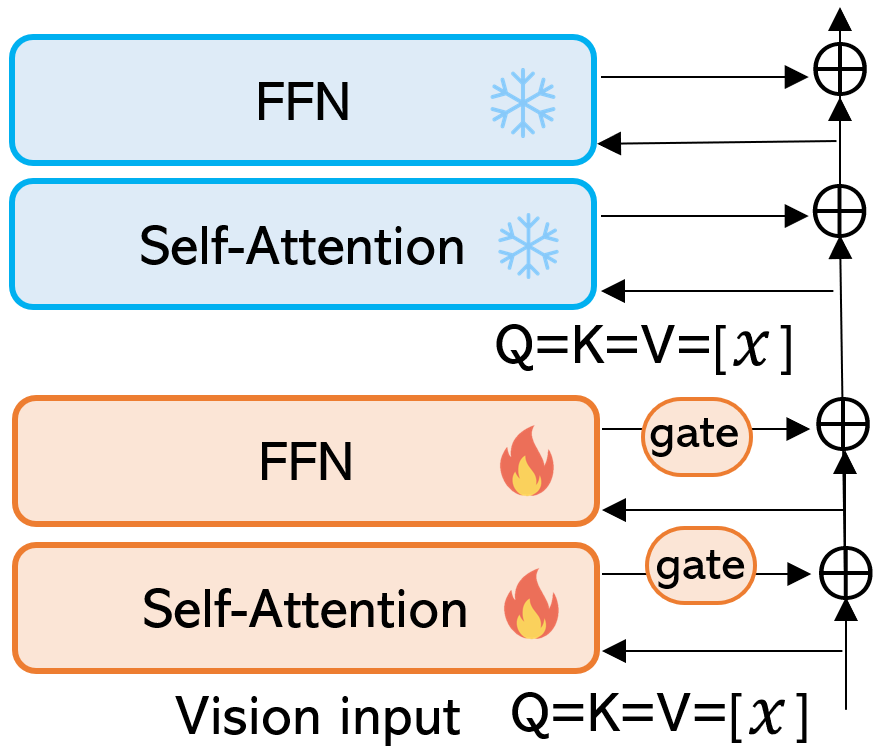
Illustrative comparisons across different model tuning methods. (a) and (b) are existing baseline tuning methods. For model customization in a target domain, In REACT, we found that (c) and (d) work better. One layer of the proposed modularized image encoder in locked-text gated-image tuning is illustrated in right side.
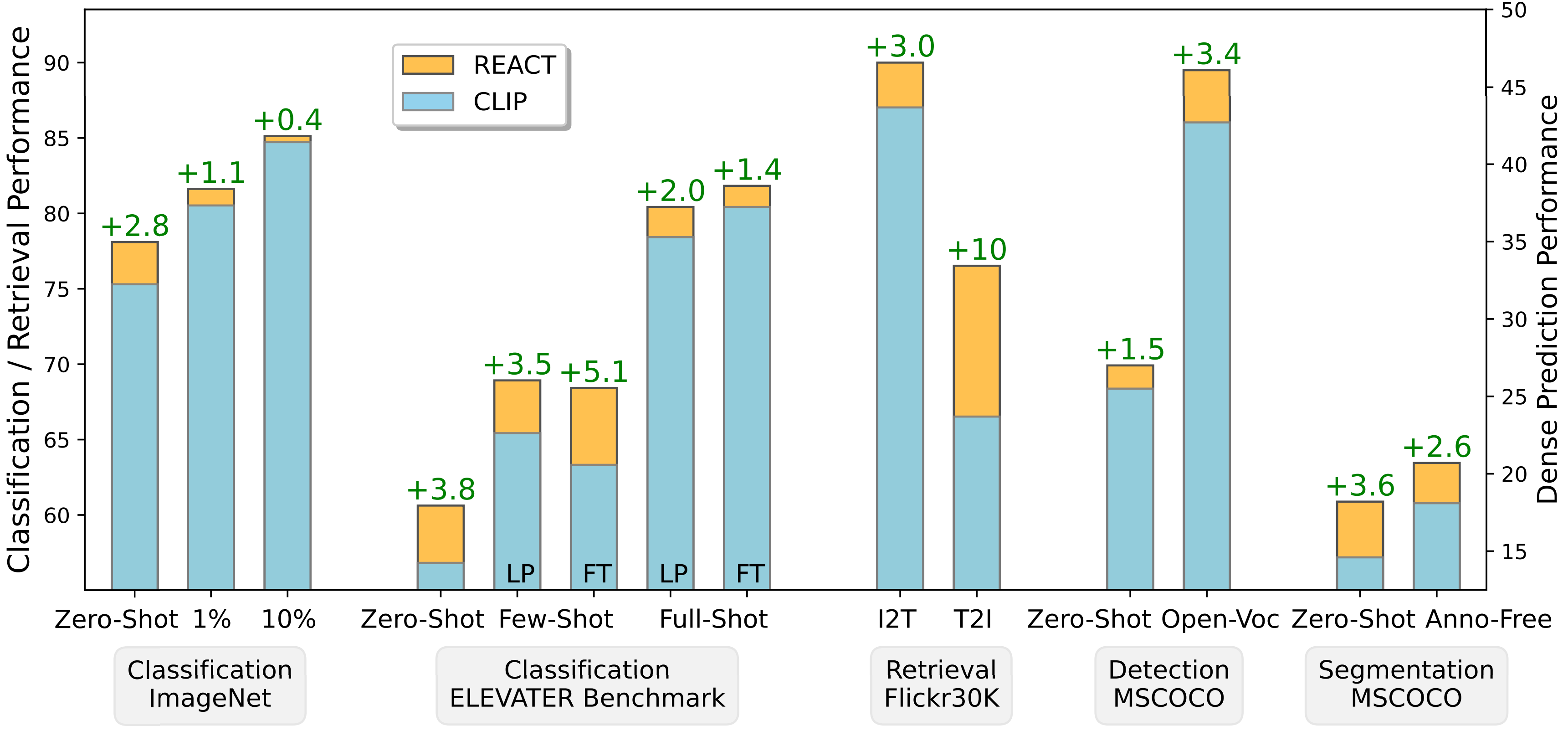
REACT consistently transfer better than CLIP on across a variety of tasks, including ImageNet classification, zero/few/full-shot classification on 20 datasets in ELEVATER benchmark, image-text retrieval, object detection and segmentation.
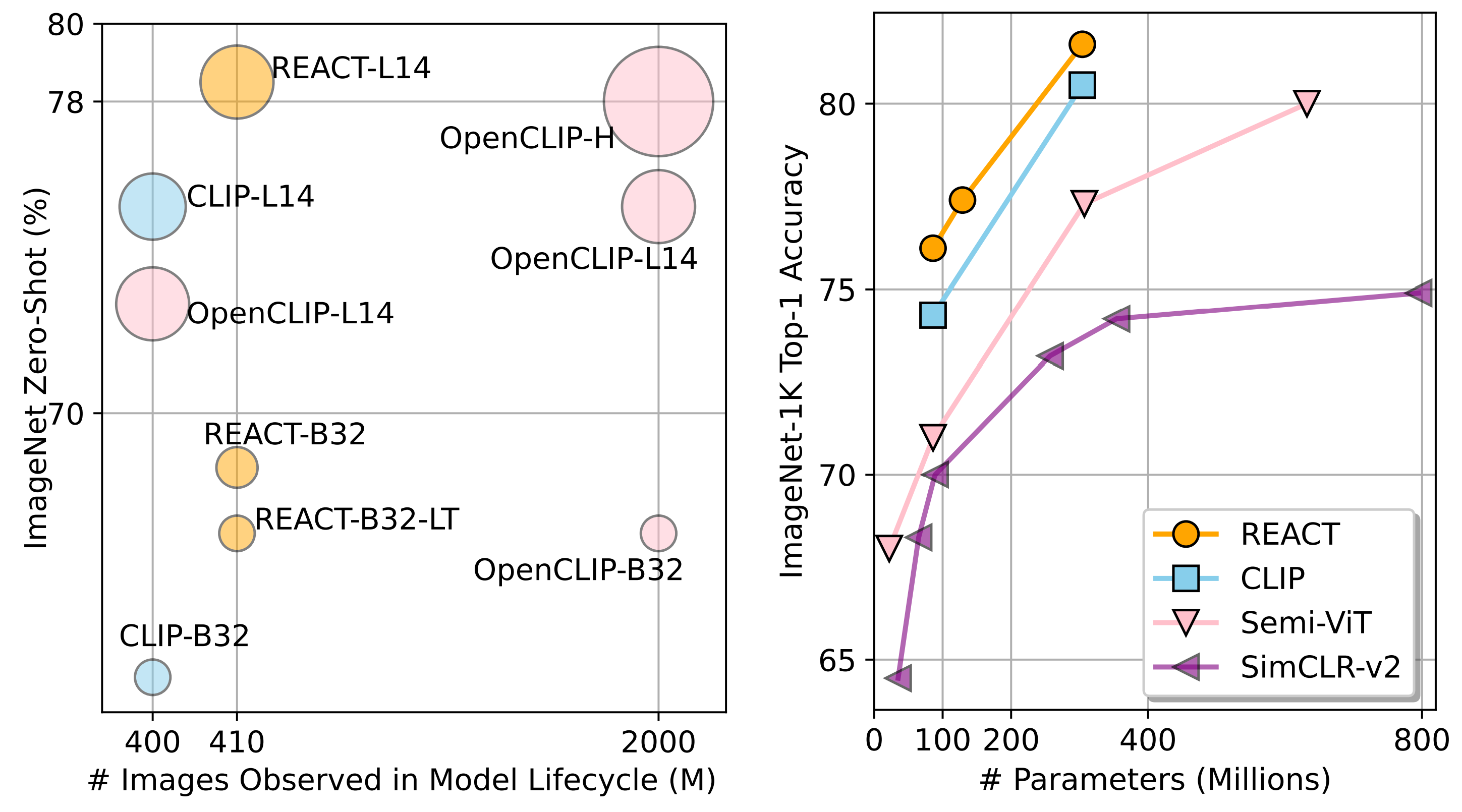
REACT achieves the best zero-shot ImageNet performance among public checkpoints with nearly 5x smaller data size (Left), and achieves the new SoTA on semi-supervised ImageNet classification in the 1% labeled data setting (Right).
@article{liu2023react,
author = {Liu, Haotian and Son, Kilho and Yang, Jianwei and Liu, Ce and Gao, Jianfeng and Lee, Yong Jae and Li, Chunyuan},
title = {Learning Customized Visual Models with Retrieval-Augmented Knowledge},
publisher = {arXiv:2301.07094},
year = {2023},
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
